RESEARCH
My research focuses on developing new systems, techniques and models to address the emerging challenges of performance, cost-efficiency and privacy in Distributed and Cloud computing systems. Our recent work addresses the challenges of Provisioning Cost-optimized and Privacy-conscious services in the Cloud with a specific focus on MapReduce-based Big Data processing. In the recent years, cloud computing and its pay-as-you-go cost structure have enabled infrastructure providers, platform providers and application service providers to offer computing services on demand and pay per use just like how we use utility today. This growing trend in cloud computing, combined with the demands for Big Data and Big Data analytics, is driving the rapid evolution of datacenter technologies towards more cost-effective, more consumer-driven, more privacy conscious and technology agnostic solutions .
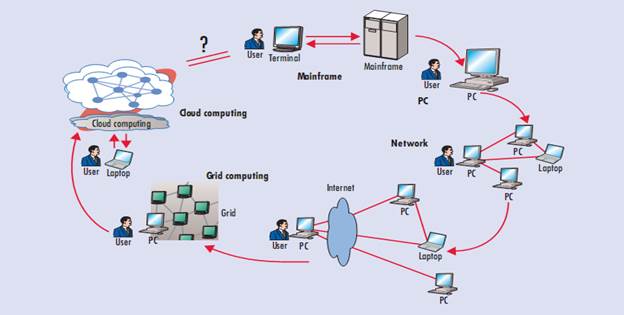
Figure 1: Computing Paradigm Shift
BIG DATA PROCESSING IN THE CLOUD:
One of the technologies that made big data analytics popular and accessible to enterprises of all sizes is MapReduce and its open-source implementation namely Hadoop. With the ability to automatically parallelize the application on a cluster of commodity hardware, MapReduce allows enterprises to analyze terabytes and petabytes of data more conveniently than ever. It is estimated that, by 2015, more than half the world's data will be processed by Hadoop. As part of our research, we have identified and tackled some of the important challenges in scaling MapReduce-based Big Data computing in Cloud datacenters.
Purlieus:
Coupled Storage Architecture for MapReduce:
The network load of MapReduce is of special concern in a datacenter as large amounts of data can be generated during the shuffle phase of the MapReduce job. As each reduce task needs to read the output of all map tasks, a sudden explosion of network traffic can significantly deteriorate cloud performance. Purlieus is a self-configurable locality-based data and virtual machine management framework that enables MapReduce jobs to access most of their data either locally or from close-by nodes including all input, output and intermediate data generated during map and reduce phases of the jobs. The first feature of Purlieus is to identify and categorize jobs using a data-size sensitive classifier to characterize jobs using four data size based footprint. Purlieus then provisions virtual MapReduce clusters in a locality-aware manner, enabling efficient pairing and allocation of MapReduce virtual machines (VMs) to reduce the network distance between storage and compute nodes for both map and reduce processing. Through this careful combination of data locality and VM placement, Purlieus achieves significant savings in network traffic and almost 50% reduction in job execution times.
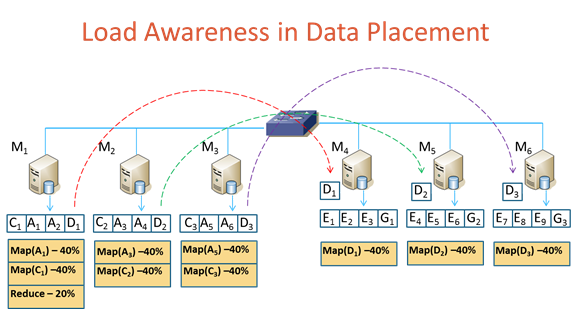
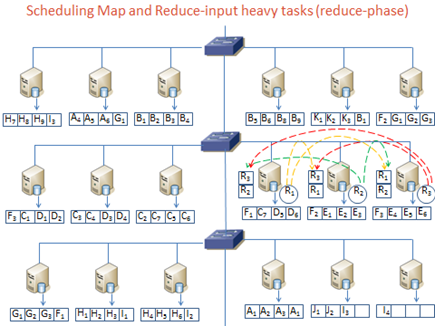
Figure 2:
Load-aware Data Placement and Reduce-locality aware Scheduling
While map locality is well understood and implemented
in MapReduce systems, reduce locality has surprisingly received little
attention in spite of its significant potential impact. As an example, Figure 3
shows the impact of improved reduce locality for a Sort workload. It shows the
Hadoop task execution timelines for a 10 GB dataset in a 2-rack 20-node
physical cluster where 20 Hadoop VMs were placed without and with reduce
locality (top and bottom figures respectively). As seen from the graph, reduce
locality resulted in a significantly shorter shuffle phase helping reduce total
job runtime by 4x. Purlieus categorizes MapReduce jobs based on how much data
they access during the map and reduce phases and analyzes the network flows
between sets of machines that store the input/intermediate data and those that
process the data. It places data on those machines that can either be used to
process the data themself or are close to the machines that can do the
processing. This is in contrast to conventional MapReduce systems which place
data independent of map and reduce computational placement -- data is placed on
any node in the cluster which has sufficient storage capacity and only map
tasks are attempted to be scheduled local to the node storing the data block.
To the best of our knowledge, Purlieus is the first effort that attempts to
improve data locality for MapReduce in a cloud.
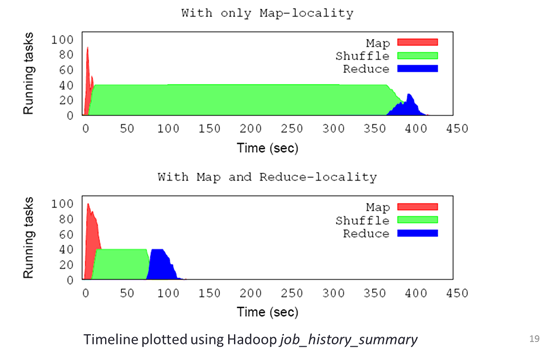
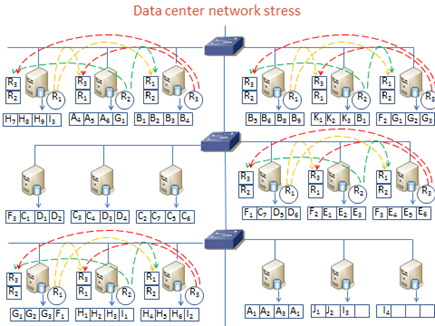
Figure 3:
Impact of Reduce Locality and Reduced Network stress
Cura: A Cost-optimized
Model for MapReduce Clouds:
One of the most challenging goals of Cloud providers is to determine how to best provision virtual MapReduce clusters for jobs submitted to the cloud by taking into consideration two sometimes conflicting requirements namely, on one hand, meeting the service quality requirements in terms of throughputs and response times and on the other hand minimizing the overall consumption cost of the MapReduce cloud data center. We propose a new Cost-optimized model for MapReduce in a Cloud called Cura. In contrast to existing MapReduce cloud services, the resource management techniques in Cura aim at minimizing the overall resource utilization in the cloud as opposed to per-job or per-customer resource optimization in the existing services. This global optimization in Cura in combination with other enhancements such as cost-aware resource provisioning, VM-aware scheduling, intelligent capacity planning and online virtual machine reconfiguration results in more than 80% reduction in the compute infrastructure cost of the cloud data center with 65% lower response time for the jobs.
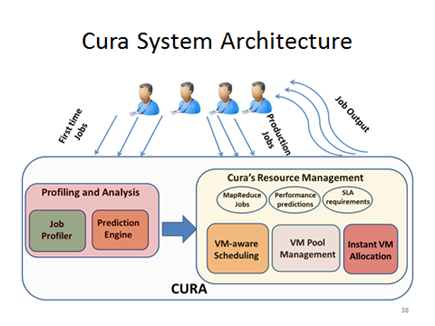
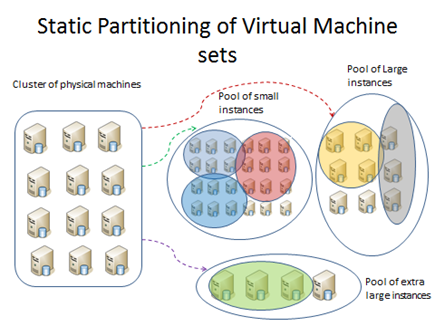
Figure 4:
Cura: System Architecture and Virtual Machine Pools
VNCache: Seamless
Caching for Bridging Compute and Storage Clouds :
Most existing services for MapReduce in the Cloud violate the fundamental design philosophy of MapReduce namely moving compute towards the data. Therefore, processing big data is inefficient with the existing Cloud storage models where data requires to be transferred from the storage cloud to the compute cloud before any jobs can be run. Further while the (often long running) job is executing, the dataset is replicated multiple times in both storage and compute clouds. We developed an efficient filesystem layer VNcache that integrates a virtual namespace of data stored in the storage cloud into the compute cluster. Through a seamless data streaming model, VNcache optimizes Hadoop jobs as they can start executing as soon as the compute cluster is launched without requiring apriori data transfer. With VNcache's accurate pre-fetching and caching, jobs often run on a local cached copy of the data block significantly improving performance. Further data can be safely evicted from the compute cluster as soon as it is processed reducing the total storage footprint. Uniquely, VNcache is implemented with no changes to the Hadoop application stack and provides a flexible control point for cloud providers to seamlessly introduce storage hierarchies including SSD based storage into the solution.
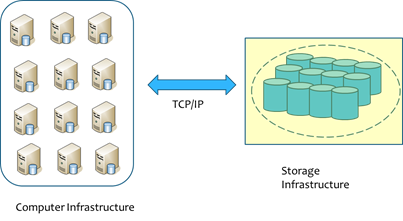
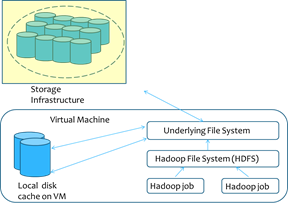
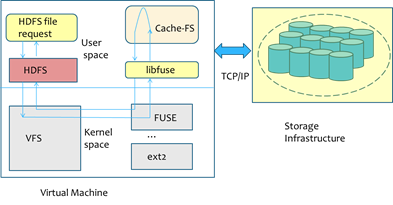
Figure 5:
VNCache: Data Flow
Reliable State Monitoring in Cloud Datacenters:
Continuously delivering accurate state monitoring results in the Cloud is difficult with transient node failures or network issues that are common in large-scale datacenters. As the scale of such systems grows and the degree of workload consolidation increases in Cloud datacenters, node failures and performance interferences, especially transient ones, become the norm rather than the exception. Hence, distributed state monitoring tasks are often exposed to impaired communication caused by such dynamics on different nodes. Unfortunately, existing distributed state monitoring approaches are often designed under the assumption of always online distributed monitoring nodes and reliable inter-node communication. As a result, these approaches often produce misleading results which in turn introduce various problems to Cloud users who rely on state monitoring results to perform automatic management tasks such as auto-scaling. This work introduces a new state monitoring approach that tackles this challenge by exposing and handling communication dynamics such as message delay and loss in Cloud monitoring environments. Our approach delivers two distinct features. First, it quantitatively estimates the accuracy of monitoring results to capture uncertainties introduced by messaging dynamics. This feature helps users to distinguish trustworthy monitoring results from ones heavily deviated from the truth, yet significantly improves monitoring utility compared with simple techniques that invalidate all monitoring results generated with the presence of messaging dynamics. Second, our approach also adapts to non-transient messaging issues by reconfiguring distributed monitoring algorithms to minimize monitoring errors. Our experimental results show that, even under severe message loss and delay, our approach consistently improves monitoring accuracy, and when applied to Cloud application auto-scaling, outperforms existing state monitoring techniques in terms of the ability to correctly trigger dynamic provisioning.
Related Publications:
· Balaji Palanisamy, Aameek Singh and Ling Liu, "Cost-effective
Resource Provisioning for MapReduce in a
Cloud", to appear in IEEE
Transactions on Parallel and Distributed Systems (IEEE TPDS 2014). (Pdf)
· Balaji Palanisamy, Aameek Singh, Nagapramod
Mandagere, Gabriel Alatore
and Ling Liu, "VNCache: Map Reduce Analysis for Cloud-archived Data", Proc. of
14th IEEE/ACM International Symposium on
Cluster, Cloud and Grid Computing (IEEE/ACM CCGrid
’14) (Pdf)
· Balaji Palanisamy, Aameek Singh, Ling Liu and Bhushan Jain, "Purlieus: Locality-aware Resource Allocation for MapReduce in a Cloud", Proc. of IEEE/ACM Supercomputing (SC' 11). (Pdf)
· Balaji Palanisamy, Aameek Singh, Ling Liu and Bryan
Langston, "Cura: A Cost-Optimized Model for MapReduce in a
Cloud", Proc. of 27th IEEE
International Parallel and Distributed Processing Symposium (IPDPS 2013). (Pdf)
· Shicong Meng, Arun Iyengar, Isabelle Rouvellou, Ling Liu, Kisung Lee,
Balaji Palanisamy and Yuzhe Tang, "Reliable State Monitoring
with Messaging Quality Awareness", Proc. of IEEE International Conference on Cloud Computing (IEEE
Cloud' 12). (Pdf) (Received Best Paper Award)
· Yang Zhou, Ling Liu, Balaji Palanisamy and Yuzhe Tang, "Memory Resource Aware Optimizations for
Large Scale Network Analysis", in
submission
· Yuzhe Tang, Arun Iyengar, Wei Tan, Ling Liu
and Balaji Palanisamy, "Lightweight Real-time Indexing for Big
Key-Value Data Systems", in
submission.
Patents:
· Balaji Palanisamy and Aameek Singh, "Locality-aware Resource Allocation for Cloud Computing", United States Patent Application No. 13/481,614
· Aameek Singh, Balaji Palanisamy, Nagapramod Mandagere and Gabriel Alatore, "Bridging Compute and Storage for MapReduce Applications in the Cloud", in submission
DATA PRIVACY AND DATA ANALYTICS:
As many analytics in the
Cloud operate on datasets that can be potentially sensitive and private,
allowing human data analysts to perform business analytics on raw data in the
Cloud may lead to privacy breaches even if the datasets are anonymized through
well-known anonymization techniques such as k-anonymization
and differential privacy. In a cloud
both data access needs to be private as well as data processing needs to be
private no matter if the access is from an application running in the same
Cloud or from a remote client device such as a mobile phone.
MobiMix: Protecting Location privacy with Road Network Mix-zones:
When it
comes to Mobile Cloud computing, one family of applications specifically raises
concern. When mobile users in a Cloud request location dependent data services
that require the locations of the clients for processing, a malicious adversary
can utilize the location trace to invade the privacy of the user. MobiMix is a
novel road-network mix-zone based framework for anonymizing location data and
serving location based service requests without disclosing privacy in
real-time. In contrast to spatial cloaking based location privacy protection,
the MobiMix approach aims at breaking the continuity of location exposure
through the development of attack resilient road network mix-zones. However
unlike the theoretical mix-zones, in a road network the timing information of
users' entry and exit into the mix-zone and the non-uniformity in the
transitions taken at the road intersection provide valuable information to an
attacker trying to break the anonymity. We developed a suite of mix-zone
construction and deployment techniques that protect mobile users against
location privacy risks by offering both timing attack resilience and transition
attack resilience even when the mobility patterns and road-network topology are
exposed to the attackers.

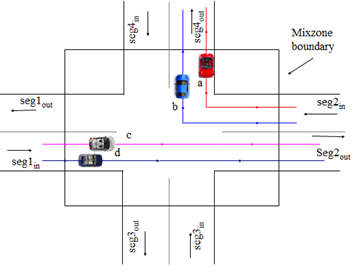
Figure 6:
Road Network Mix-zones for Anonymous Location-based Applications
Anonymizing
Continuous Queries of Mobile users:
Continuous
location based services represent queries that are continuously evaluated along the trajectory of a mobile user either
periodically or aperiodically. While MobiMix road network mix-zone approach
works well against attacks based on road network characteristics, they are
vulnerable to attacks based on the temporal, spatial and semantic correlations
of location queries. To protect continuous query users, We developed three
types of delay-tolerant road network mix-zones (i.e., temporal, spatial and
spatio-temporal) that are free from CQ-timing and CQ-transition attacks and in
contrast to conventional mix-zones, perform a combination of both location
mixing and identity mixing of spatially and temporally perturbed user locations
to achieve stronger anonymity under the CQ-attack model. Based on experiments
on large scale geographic maps, we find that by combining temporal and spatial
delay-tolerant mix-zones, we can obtain the strongest anonymity for continuous
queries while making acceptable tradeoff between anonymous query processing
cost and temporal delay incurred in anonymous query processing. Overall, the
delay-tolerant mix-zone approach provides higher level of anonymity while
offering better quality of services for location based services with hard
continuity constraints.
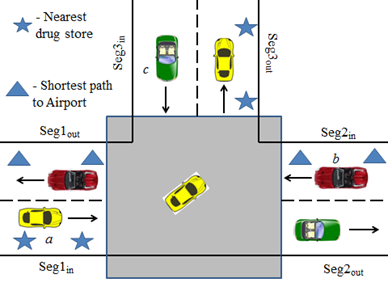
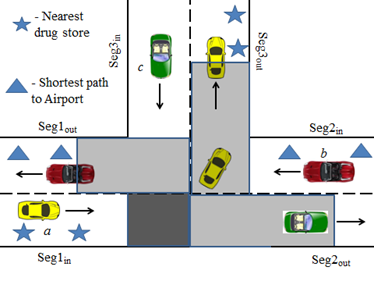
Figure
7:Continuous Query attacks on Rectangular and Non-rectangular Road Network
Mix-zones
PrivacyCloud: Privacy-preserving Access control of Large Datasets:
Most
existing privacy techniques protect the privacy of the individual associations
with the sensitive attribute while providing the utility of the anonymized data
in terms of aggregate results. However, analytics on datasets providing
accurate aggregate results may not protect the privacy under scenarios where
the aggregate information by itself is sensitive, such as analytics related to
business intelligence. The PrivacyCloud framework
addresses this concern through the development of a new class of cryptographic
anonymization schemes which deals with anonymizing graph datasets to protect
utility at different levels such as graph structure, aggregate information and
invidual associations. Thus, PrivacyCloud offers the ability for the Cloud
provider to provide privacy controlled data utility customized based on
per-customer access privilege levels. We firmly believe that an important
privacy enabling technology for cloud services is the ability to offer privacy
controlled data utility customized based on per-user access privilege levels
which cryptography driven anonymization schemes accomplish efficiently.
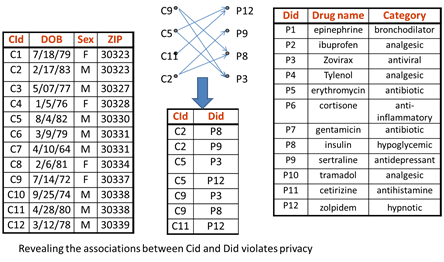
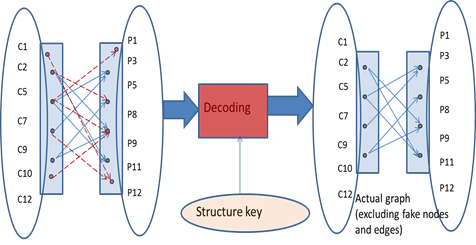
Figure 8:An
Example showing Cryptographic Anonymization and Decoding
Privacy-Preserving
Indexing for eHealth Information Networks:
The past few years
have witnessed an increasing demand for the next generation health information
networks, which hold the promise of supporting large-scale information sharing
across a network formed by autonomous healthcare providers. One fundamental
capability of such information network is to support efficient,
privacy-preserving (for both users and providers) search over the distributed,
access controlled healthcare documents. In this paper we focus on addressing
the privacy concerns of content providers; that is, the search should not
reveal the specific association between contents and providers (a.k.a. content
privacy). We propose SS-PPI, a novel privacy-preserving index abstraction,
which, in conjunction of distributed access control-enforced search protocols,
provides theoretically guaranteed protection of content privacy. Compared with
existing proposals (e.g., flipping privacy-preserving index), our solution
highlights with a series of distinct features: (a) it incorporates access
control policies in the privacy-preserving index, which improves both search
efficiency and attack resilience; (b) it employs a fast index construction
protocol via a novel use of the secrete-sharing scheme in a fully distributed
manner (without trusted third party), requiring only constant (typically two)
round of communication; (c) it provides information-theoretic security against
colluding adversaries during index construction as well as query answering. We
conduct both formal analysis and experimental evaluation of SS-PPI and show that
it outperforms the state-of-the-art solutions in terms of both privacy
protection and execution efficiency.
Related Publications:
· Balaji Palanisamy and Ling Liu, "Attack-resilient Mix-zones over Road Networks: Architecture and Algorithms" to appear in IEEE Transactions on Mobile Computing (IEEE TMC 2014). (Pdf)
· Balaji Palanisamy, Ling Liu, Kisung Lee, Shicong Meng, Yuzhe Tang, "Delay-tolerant Mix-zones on Road Networks", in Distributed and Parallel Databases (DAPD 2013). (Pdf)
· Balaji Palanisamy and Ling
Liu, "Effective Mix-zone Anonymization for Mobile Travelers”, in Geoinformatica 2013. (Pdf)
· Balaji Palanisamy and Ling Liu, "MobiMix: Protecting Location Privacy with Mix-zones over Road Networks", Proc. of 27th IEEE International Conference on Data Engineering (ICDE' 11). (Pdf)
· Balaji Palanisamy, Ling Liu, Kisung Lee, Aameek Singh and Yuzhe
Tang, "Location Privacy with Road Network Mix-zones", Proc. of 8th IEEE International Conference on
Mobile Ad-hoc and Sensor Networks (IEEE MSN'12). (Pdf)
· Yuzhe Tang, Ting Wang, Ling Liu, Shicong Meng, Balaji Palanisamy, "Privacy Preserving Indexing for eHealth Information Networks", Proc. of 20th ACM Conference on Information and Knowledge Management (CIKM' 11) (Pdf)
· Balaji Palanisamy, Sindhuja Ravichandran, Ling Liu, Binh Han and Kisung Lee, "Road Network Mix-zones for Anonymous Location Based Services", Demonstration at 28th IEEE International Conference on Data Engineering (ICDE' 13). (Pdf)
· Kisung Lee, Ling Liu, Shicong Meng, Balaji Palanisamy, "Road Network Aware Spatial Alarm Processing", Proc. of IEEE International Conference on Web Services (ICWS' 12). (Pdf)
· Kisung Lee, Ling Liu,
Binh Han, Balaji Palanisamy,
"ROADALARM: a Spatial Alarm System on Road Networks", Demonstration
at 28th IEEE International Conference on Data Engineering (ICDE'
13). (Pdf)
· Apurva Mohan , David Bauer, Douglas M. Blough, Mustaque Ahamad, Bhuvan Bamba, Ramkumar Krishnan, Ling Liu, Daisuke Mashima, Balaji Palanisamy, "A Patient-centric, Attribute-based, Source-verifiable Framework for Health Record Sharing", GIT CERCS Technical Report No. GIT-CERCS-09-11, 2009, Georgia Institute of Technology, Atlanta, GA, USA. (Pdf)
· Mustaque Ahamad, Douglas Blough, Ling Liu, David Bauer, Apurva Mohan, Daisuke Mashima, Bhuvan Bamba, Balaji Palanisamy, Ramkumar Krishnan, Italo Dacosta, and Ketan Kalgaonkar, "MedVault: Health Professional Access to Source-Verifiable Patient-Centric PHR Repository", at poster session in 19th Usenix Security Symposium, (USENIX Security' 10).
· Priyanka Prabhu, Shamkant B. Navathe, Stephen Tyler, Venu Dasigi, Neha Narkhede, Balaji Palanisamy, "LITSEEK: Public health literature search by metadata enhancement with External knowledge bases", in workshop of 18th ACM Conference on Information and Knowledge Management (CIKM' 09 ) (Pdf)
· Balaji Palanisamy and Ling Liu, " Privacy-preserving
Publishing of Multi-level Utility-controlled Graph Datasets ", in submission
· Kisung
Lee, Ling Liu, Balaji Palanisamy et.al., Road
Network-Aware Spatial Alarms", in submission
COMPUTER NETWORKING AND
NETWORKED SYSTEMS:
Our past research in Computer Networks and Networked
systems was primarily focused on Performance optimization of Optical WDM
Networks. In particular, we have developed Distributed Reconfiguration
techniques for Optical WDM Networks for adapting them for changes in the
network traffic conditions and for handling faults in the events of a link or
node failure. We have also developed scalable multicast traffic grooming
algorithms for efficiently routing multicast traffic in sparse splitting
Optical WDM Networks.
Distributed
Reconfiguration of Optical WDM Networks:
In IP-over-WDM
networks, an all optical path (lightpath) is established between any two IP routers,
so that data transfer between them is done in optical form. Thus a set of
lightpaths that are established a priori defines the virtual topology of a WDM
optical network. In the event of a link or node failure, the virtual topology
may be partitioned into a number of sets of nodes. It results in a scenario
where a node belonging to one set cannot communicate with nodes in the other
sets. The failure may also affect the objective function value leading to
decreased network performance. In such a case, it may be indispensable to
restore the connectivity in the virtual topology and improve the network
performance in terms of objective function value. In this work, we propose a
two-phase distributed algorithm for virtual topology reconfiguration in the event
of link and node failures. The algorithm restores the failed connectivity
during phase I. Phase II of the algorithm improves the network performance by
bringing down the objective function value. The performance of our algorithm is
through extensive simulation experiments.
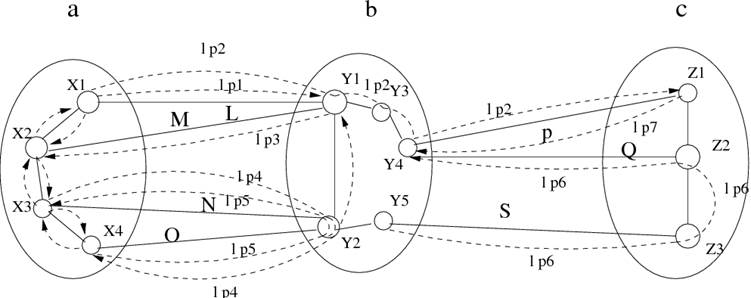
Figure 8:An
example illustrating formation of connected components after link failure
Grooming of Multicast
Sessions in Sparse Splitting WDM Mesh Networks:
Cost effective grooming of several sessions with fractional wavelength
bandwidth onto a single wavelength has become prominent in WDM networks. In
this work, we address the problem of routing and wavelength assignment of
multicast sessions with sub-wavelength traffic demands in sparse splitting WDM
networks. We assume a sparse splitting node architecture in which only a few
nodes in the network are split-capable. A node with splitting capability can
forward an incoming message to more than one outgoing link in the optical form.
The multicast capability at the non-split nodes can be achieved by converting
the optical signal into electronic form and transmitting in optical form onto
all the required outgoing links. However, the traffic duplication at the electronic
level is more expensive than the optical level in terms of the delay incurred
due to the optical-electronic- optical (O/E/O) conversion. We study the problem
of assigning routes and wavelengths to the multicast sessions with the
objective of minimizing the resources required for electronic copying. Since
the multicast traffic grooming problem is computationally intractable, we adopt
a heuristic approach called VSGroom. The performance of the proposed technique
is studied and compared through extensive simulation experiments.
Reliability-differentiated Routing in
Optical Burst Switched Networks:
Optical burst
switching (OBS) is one of the most promising next generation all-optical data
transport paradigms that allows dynamic sub-wavelength switching of data. As networks become increasingly distributed and autonomic,
Optical Burst Switching becomes the right choice for the next generation
optical Internet. In this work, we propose a mechanism for Dynamic Routing of
Reliability-Differentiated connections (DRRDC) in Optical Burst Switched
networks. The proposed mechanism consists of two schemes namely Adaptive
Routing, a loss minimization mechanism that selects the least congested route
for burst scheduling and Adaptive Burst Cloning, a technique for providing loss
recovery in an OBS network. We develop a network simulation model to
investigate the proposed DRRDC scheme and compare its performance with the
existing prioritized burst scheduling QoS scheme. Our results show that the
proposed service differentiation mechanism has a significantly low packet loss
compared to the existing prioritized burst scheduling scheme in an optical
burst switched network.
Related Publications:
· Balaji Palanisamy, T.Siva Prasad, and N.Sreenath, "Traffic Adaptive
Wavelength Routing in IP-Over-WDM Networks", in Proc. 14th
International conference on Advanced Computing and Communications, (ADCOM'
06) (Received
Best Paper Award)
· N.Sreenath and Balaji Palanisamy, "An Online Distributed Protocol for the Restoration of Connectivity in the Virtual topology after Link failure in IP over WDM networks", in Proc. International conference on Networking and Services, Silicon Valley, (ICNS' 06) . (Pdf)
· N.Sreenath , Balaji Palanisamy, and S.R.Nadarajan, "Grooming of Multicast Sessions in Sparse Splitting WDM Mesh Networks using Virtual Source Based Trees", in Proc. International Conference on Systems and Networks Communication, (ICSNC' 06). (Pdf)
· N.Sreenath and Balaji
Palanisamy, "A Two-Phase Distributed
Reconfiguration Algorithm for Node Failures in IP-Over-WDM Networks",
in Proc. International Conference on Systems and Networks Communication,
(ICSNC' 06).
· Balaji Palanisamy, "PeerTalk: A Secure, fully Decentralized Peer-to-peer Instant Messaging System", in Proc. International Conference on Information Security, (ICIS' 05)
· N.Sreenath, N. Devendra and Balaji Palanisamy, "Dynamic Routing of Reliability-Differentiated Connections in Optical Burst Switched Networks", in Proc. Managing Complexity in a Distributed World, IISc Centenary Conference, (MCDES' 08). (Pdf)