University of Pittsburgh, Pittsburgh, Pennsylvania, USA
ABSTRACT: An architecture or reference model helps to promote clear compatible standards. This paper examines the implicit architectures and reference models for the next generation of the web. We first consider the problem by looking at the standards and the standardization process in terms of the goals those standards attempt to achieve. We then examine five significant efforts with an eye to how they can contribute to the design of the next generation web. The paper concludes with a framework for an architecture for the next generation web in terms of its goals, major components, and criteria for assessment.
Historically, there have been four basic interfaces for a computer process – networks, operating systems, humans, and data. The network interface is normally layered in some way consistent with the Open System Interface Reference Model (OSIRM). Most operating system interfaces are described in accord with the Portable Operating System Interface – POSIX. Microsoft’s Hardware Abstraction Layer (HAL) is an example of layering related to operating systems. Human Interaction could be guided by something like the Human-Computer Interaction Reference Model (Spring 1991). Spring (Spring 1999) put forward a view of data modeling that endeavored to posit the many existing standards in a framework. These interface reference models both support and constrain what can be done.
Conceptually, the standards for the next generation web overlay of the operating system, data, and network interfaces with a focus on distributed applications. This paper suggests that the standards that have been proposed are designed for different and potentially incompatible goals. Attention to these goals and the structure of the standards architecture should help to assure a more robust, flexible, and extensible infrastructure. From a standardization perspective, this begs the question of what process is most likely to yield viable, flexible, robust standards. Historically, the formal standards process built by ISO and the various national standards groups successfully tackled these tasks. However, it is generally believed that these organizations move too slowly to meet current demands. Organizations such as the IETF have demonstrated the ability to develop suites of standard, but the process is less deterministic. Consortia such as the Object Management Group have developed solid architectures, but seemed to lack the clout to insure they are implemented. Like OSIRM, the Common Object Request Broker Architecture (CORBA) has played a role in shaping many efforts and is seldom given the credit it is due.
The World Wide Web Consortium (W3C) appears to be more successful, working with the IETF to build an ISO like solution. Finally, it should be noted that in lieu of voluntary consensus standards, proprietary solutions may emerge from industry, e.g. .NET or JXTA.
Standardization has changed dramatically in the last decade. The Office of Technology Assessment (Garcia, 1992), Weiss and Cargill (Cargill 1992), Weiss (Weiss 1993), Oksala, Spring and Rutkowski (Rutkowski 1996), and Cargill (Cargill 2000) have discussed the changing nature of the standardization landscape. They highlight the problems with the formal standards development process and the more recent efforts of consortia. In summary:
A review of current efforts makes clear that the players are taking different approaches. The situation in which we find ourselves bears a striking resemblance to the classic story of the blind men describing the elephant – made even more complicated by the fact that the elephant is less like the physical elephant of the story and more like the pink elephant of a drunk’s revelry – i.e. not only are different parts being examined, but each blind man has envisioned a different elephant form!
Information technology standardization is complicated by three forces. First, because the design is in the realm of the artificial as described by Simon (Simon 1981, pp 7-8), the issue is less one of describing what is and more one of describing what “ought” to be. Cargill contends that standards have migrated from the realm of technological decisions made by engineers to marketing decisions made by organizations (Cargill 1996, pp 168-175). Second, the design is carried out in advance of the products and systems it will support. The standards are anticipatory (Spring & Bonino, 1994). The design must support technologies and efforts that have not yet been built. Third, the design is complicated by evolutionary nature of the systems. As Spar (Spar 2001, pp 11-22) has pointed out, major communication/business revolutions have at least four distinct stages – innovation, commercial development, creative anarchy, and rules.
This current revolution is nearing or the fourth stage – which she calls “rules”. The situation can be visualized in the large as one that requires frameworks, stacks and/or an infrastructure to support technology and processes directed to some need or opportunity. Simon generally, and Cargill with respect to standards, point to the importance of defining goals for the design. The shape of the standards for infrastructure, framework, and technology are all fashioned by the goals. For the US interstate system, military goals shaped infrastructure standards such as road grades and overpass dimensions. It is interesting to think about how the internet would be shaped differently today if the Domain Name System had been shaped by the proposal put forward by David Mills rather than the proposal put forward by Jon Postel. David Mills, thinking about the problems of internet mail, wrote RFC 799 in September of 1981 as a proposal for internet domain names. Given Mills goals, the document focused narrowly on a naming scheme that would support mail. Jon Postel and Saw-Zing Su published RFC 819 in August of 1982 with the intent of providing a “domain naming convention for internet user applications”. What is significant in this example is that rather than developing a standard for a particular technology, the decision was made to standardize an infrastructure that might be used my multiple technologies. (Including all of the mail and DNS related standards in the references would inappropriately bloat this reference list. The interested reader should review the earlier RFC’s in the mail and DNS RFC chains. They are most illuminating. MAIL: 733, 821, 822; DNS: 226, 247, 799, 819, 882, 883, 973, 1034, 1035, 1591.)
Five current “architectures” are selected for review. There are literally hundreds of contenders for infrastructure architectures that might lead to the next generation web. We briefly look at five of them as a prelude to a proposal for a process for developing a next generation architecture based on standards. The criticisms are intended to suggest ways they might be recast or combined to provide better support for the next generation infrastructure. As the reader will note, these various efforts are very different. They include implicit and explicit proposals for infrastructure, service stacks, and frameworks.
Design goals are implicit in some of the architectures proposed. Microsoft’s .NET and IBM’s WebSphere are unabashedly devoted to business applications and business transactions. SUN’s JXTA and HP’s e-services focus on federated systems that support ad hoc peer-to-peer interactions. A more explicit set of goals may be obtained from projections of the future of the web. Broda (Broda 2001) suggests that there are six distinct futures for the web – traditional, entertainment, pervasive, e-commerce, pocket communicator, and voice activated. Each has different characteristics and requires different support structures. All of these will be some part of the computing fabric of the future. It will be important that the architecture support, or at least not preclude, the development of technologies in all these areas. Visions of the next generation of computing provide some broader guidance. There are dozens of high level visions – Negroponte’s (Negroponte 1995) vision of digital media, Berner-Lee’s (Berner-Lee 1999) vision of a semantic web, and Dertouzos’s (Dertouzos 1997) vision of information marketplaces.
The Common Object Request Broker Architecture developed in the late 1980s, extended the client server model and provided solutions for rendezvous that extended RPC. It provided a framework for application development with the intent of reducing, like RPC, the coding complexity for distributed applications. Clearly, the vision of CORBA extended to enterprise systems and supply chain systems. CORBA predated the resource type systems resulting from the success of the web. CORBA was one of the first efforts to define the core services that would be provided in support of the distributed components.
Common facilities included information management, system management, and task management. The object services included naming, lifecycle, security, persistence, concurrency, collection, and properties, to name only a few of the more than 15 services defined for implementation in ORBS. Like OSIRM, CORBA provided a heavyweight solution for distributed applications, and like OSIRM was considered too heavy for easy implementation although it is likely, before all is said and done, that the final solution will look very CORBA like. What the OMG did propose, which has found its way into subsequent proposals, is an architecture using Object Request Brokers (ORBs) as intermediaries for objects, both as location tools and wrappers or mediators.
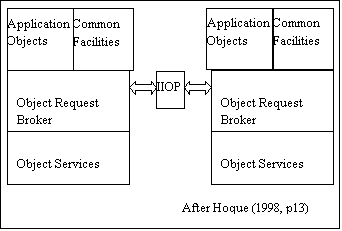
E-speak (Hewlett-Packard 1999) was an early player in the second generation of systems designed to support object location and access. Just as XML evolved from SGML and dropped many of the provisions designed for an era of primitive editors, so e-speak appears as a second generation ORB. The increased sophistication of development environments and programming languages obviated the need for an extensive framework built into the ORB, thus reducing its complexity and focusing its energies on the core processes. Further, e-speak appears to have been designed in large part for a world of intelligent devices – not surprising given the preeminence of HP in the printer and medical device arena. It provided access to named resources in a federated system. The notion of a distributed and federated repository or directory service was central to the system.
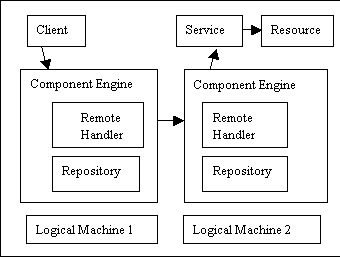
Microsoft’s .NET is one part of its strategy for market share in the development of the next generation web. It is based on Microsoft’s manifestation of an ORB-DCOM. As presented, .NET is a framework for software development. Microsoft (Microsoft 2002) has defined the architecture as shown below. Unlike the OMG and HP designs, the layering is more explicitly directed to operational functionality than it is to conceptual functionality. To the extent that Microsoft defines the goal of the effort, it is in terms of rapid prototyping of business services.

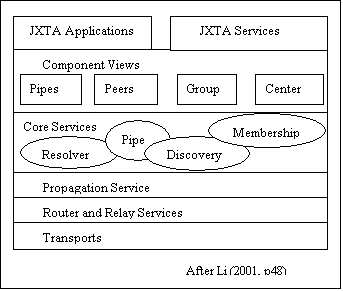
Li (Li 2001) provides a high level overview of the JXTA architecture. SUN introduced JXTA as another in the family of standards developed based on Java. What is perhaps most appealing about JXTA is the focus on simplicity. Influenced by the success of Java and by SUN’s long interest in networked services and intelligent devices, JXTA appears to combine the best of CORBA, e-speak, and advances in peer-to-peer systems to provide a simple streamlined architecture. While it accounts for the web and web resources, it is more focused on processes than resources. Like e-speak, it has a strong focus on federated and ad hoc systems.
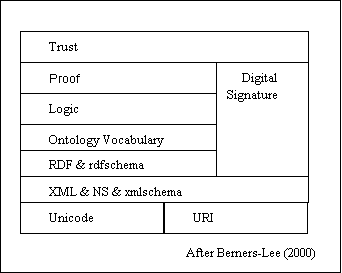
The Berners-Lee (Berners-Lee 2000) architecture for the semantic web is cited frequently. Looking at the architectures described above, one cannot help but be impressed with the distinctively different flavor of the architecture. While Berners-Lee surely envisions a web where resources are applications and services as well as documents, they do not appear in this architecture. While it is clear what is intended by many of the layers, it is not clear how the functionality is layered. Thus, that trust is based on digital signatures is logical, but it is not clear why they would be applied to RDF schema and not to XML schema. Why proof is separated from logic is not clear. Why the bottom layers are defined by operational standards and the top layers by high level concepts is equally not clear. However, what is most important about the semantic web architecture is that it defines radically different “ought” for the design. It focuses on the location of resources in an environment where the mechanisms for description of the resources are not controlled centrally.
Each of these models contributes to an understanding of the next generation web. A detailed analysis and criticism is neither the intent of this paper, nor of particular importance at this point. One can be gleaned from this quick review are four points:
In the next section, we propose steps that may facilitate the development of a comprehensive architecture.
There are several competing goals for the next generation of the web which need to be recognized and harmonized. The efforts do not make explicit whether they are intended as frameworks, service stacks, and infrastructures. Finally, it is not always clear that criteria for assessing the conceptual functionality of the standards are being applied. Standardization for the next generation web would be enhanced if these three issues were addressed explicitly. While no particular answers are intended, positions in these three areas are articulated below as way to begin this discussion.
There are three basic goals that may be derived from the work cited above and a variety of other sources. We offer them here in the hopes that they will be of some use in framing the debate. The goals proposed below are co-equal in importance.
Allow for extended or augmented collaboration and communication. This goal is focused on human to human communication augmented by computer. It excludes surrogate activity and communication through artifacts, which are dealt with explicitly in the next two goals. The internet allows people to communicate and collaborate fully and completely without respect to time and space. Thus, just as the car and highway system made the suburbs possible living locations for co-workers, so the next generation web may allow effective and full collaboration and communication from any place on the planet. Our financial advisor, doctor, lawyer, or co-worker may communicate and work intimately and fully with us across vast distances and without regard to minor differences in clock time. The focus of technology in support of this goal is on the richness of the communication channel that can be opened up between humans. This will require not only symbolic data, but digitized analog information and information such as is represented by the “social periphery”.
Allow surrogates to interact with each other.This goal deals with programs and processes that interact on behalf of, or independently of, the human via the web. We choose the term surrogate rather than agent or object because we believe it is less encumbered with existing meaning and allows for a fuller set of possibilities. A computer program, whether it manages stock trading, inventory, or a calendar, is simply a surrogate. The next generation web needs to support the interaction between surrogates of all types. We would suggest that surrogates might effectively be classed along three dimensions – autonomy of the surrogate, degree of standardization in the surrogate interface, and what is represented, e.g. person, organization, resources, process, etc. With the range and scope of surrogates that might be envisioned defined, it will be more likely that an infrastructure will be open and scalable.
Allow resources to be stored, found and accessed. The notion of the web as a huge hypertext system linked as seen fit by the individual participants in the process is a frightening prospect for us. While the nature of the interconnections on the web is far from random, it is also far from organized. One of the dominant underlying visions for hypertext comes from Bush’s article “As We May Think”. This vision was in reality a personal hypertext system for a research scientist. His conjecture that we store and retrieve information by association was an introspective observation, not an objective one. Indeed, for more than 2000 years, we have been storing and retrieving information by classification. As the web moves to metadata systems, the goal is to reintroduce a system of classification. Recent work by Buranarach (Buranarach 2002) seeks to define a system that uses both of these forms of storage and retrieval and adds a third. Buranarach calls his system ACD – association, classification, and deduction. These are indeed three distinct search approaches and will require different infrastructures to support storage and retrieval of resources of all forms.
While we believe these goals provide a reasonable starting point for assessing the next generation web infrastructure, we believe that dialog and debate are the ultimate source of an informed set of goals. We are concerned that these goals, the “oughts” of the design are not at this time explicit enough to guide the development efforts
It is possible to standardize at a number of levels, e.g. infrastructure, stacks, and frameworks. Infrastructure services are embedded in the network and are not directly linked to the application or the machine operating system in which it runs. Stack services are associated with machines or ORBs, but not with a particular application. Finally frameworks (Carey & Carlson, 2002) provide standard functionality for a given class of application. As an example, a client server program makes use of all three. Consider the design of a program using RPC or RMI. RPC itself represents a framework for application development even if it is simple by today’s standards. For purposes of discussion XDR (RPC) or interfaces (RMI) are considered a part of the standardized application framework, as are the skeletons and stubs constructed by rpcgen and rmic respectively. These systems make use of TCP or UDP to package data for transmission over the internet. While both are layered services, they are a part of the network interface on each machine, TCP is probably a more prototypical example of what we think of as a layered interface service. Finally, the Domain Name Service (DNS) may be used to determine the location of the target server. DNS is an example of infrastructure. Below we briefly describe possible infrastructure and services. From our perspective, frameworks, such as Microsoft’s .NET are outside the scope of important standardization.
Technological innovation can be supported or constrained by infrastructure. There are times when it is difficult to separate technology from infrastructure. An infrastructure dedicated to a single powerful and stable technology may be effective. Technology devoted to one infrastructure may not work effectively in another. While technologies will come and go, infrastructures tend to persist for long periods of time and may constrain or prohibit technology development. The current efforts need to carefully separate out infrastructure and accord it the special status it deserves. If Mills proposal for domain naming based on the needs of mail had been adopted rather than Postel’s more generic naming service, it is not clear just how much the current internet and the services over it would differ. In any case, we suggest that serious attention be paid to defining the infrastructure services essential for the semantic web. We would suggest the following as possible candidates.
Stack services are those that provide more or less universal functionality that is best positioned at the application interface. We would suggest that security and transaction functionality are two examples of services that might be so positioned.
Any standardization effort should be subject to three assessment criteria. The first is the positioning of the functionality to be standardized. Is it a part of the individual resource or process (framework), a part of the operating system or engine used by collections of services/resources (stack service), or is it a part of the infrastructure. The focus of our work here has been on the infrastructure or network requirements. Once functionality if correctly positioned, it has to be correctly partitioned. As in the OSIRM, the first question has to do with vertical partitioning. Are there natural boundaries in the sequence of providing a function that allow the functionality to be partitioned such that the replacement of one step in the sequence has minimal impact on the other steps. At each layer so defined, the service should then be horizontally partitioned to as to isolate the distinct functionality. Finally, each of these sub services needs to be examined to ascertain the robustness, scalability, and extensibility. Carpenter (Carpenter 1996) and Berners-Lee (Berners-Lee 1998) define a set of additional principles that they believe characterize internet infrastructures. These include heterogeneity, scalability, performance (efficiency), simplicity, modularity, tolerance, and self-description. Recognizing that this is an infrastructure for distributed applications, we can add in the demands recognized for distributed computing – concurrency, fault tolerance, security, storage, naming, etc.
Standards for e-commerce are emerging from a variety of different sources. This paper views these emerging standards in the context of the standardization process and in the broader view of the science of the artificial as described by Simon (Simon 1981). It is also informed by an examination of the import of infrastructure on technology and technological development. The paper suggests that these various efforts would be better informed by a careful examination of the goals and needs for standardization.
As predicted by Spring and Weiss (Weiss 1995), reference models to guide the standardization efforts are under provided in the context of ad hoc standardization by vendors and consortia. The lack of a clear reference model makes it difficult to compare and contrast the various efforts and to understand how they contribute to the development of new capabilities. Analysis shows the selected standardization efforts include frameworks, stack services, and infrastructure. For the purposes of this analysis, infrastructure services are those provided by the network independent of any particular system, e.g. the Domain Name Service. Stack services are local system infrastructure used by multiple applications on a system, e.g. TCP. Frameworks, which are considered to be outside the scope of this analysis, facilitate the development of applications.
The various efforts could be disambiguated by articulation of the specific goals they seek to achieve, classification of the efforts in terms of positioning and partitioning, and assessment in terms of general and internet specific software quality assessment criteria. Three broad goals that could serve to begin the discussion of what needs to be built are suggested – augmented communication and collaboration, support for surrogates, and resource classification. Within the context of these goals we suggest specific functional capabilities that may be provided by a new infrastructure – resource location, vocabulary management, and network storage. Possible enhancements to end-to-end system services – security and transaction management – are also suggested.
Berners-Lee, T. Hendler, J. & Lassila, O 2001. The Semantic Web. Scientific American: 35-44.
Berners-Lee, T. 1999. Weaving the Web. Harper.
Berners-Lee, T. 1998. Principles of Design. http://www.w3c.org/DesignIssues/Principles.html .
Berners-Lee, T. 2000. Semantic Web on XML. XML 2000.
Broda, H. 2001. The Six Faces of the Web. Sun Journal 5(2).
Carey, J. & Carlson, B. 2002. Framework Process Patterns: Lessons Learned Developing Application Frameworks. Boston: Addison Wesley.
Cargill, C. 1996. Open Systems Standardization: A Business Approach . Upper Saddle River: Prentice Hall.
Cargill, C. 2000. Evolutionary Pressures in Standardization: Considerations On ANSI’s National Standards Strategy Subcommittee On Technology, Committee On Science, U.S. House Of Representatives The Role Of Standards In Today’s Society And In The Future.
Carpenter, B. 1996. RFC1958: Architectural Principles of the Internet. Internet Architecture Board ftp://ftp.isi.edu/in-notes/rfc1958.txt .
Cherry, S.M. 2002. Weaving A Web of Ideas. Engines that search for meaning rather than words will make the Web more manageable. IEEE Spectrum Online .
Dertouzous, M. 1997. What Will Be. Harper.
Hawke, S. 2002. How the Semantic Web Works http://www.w3.org/2002/03/semweb/.
Hendler, J. & Parsia, B. 2002. XML and the Semantic Web. It's Time to Stop Squabbling -- They're Not Incompatible . XML Journal 3(10).
Hewlett Packard Co. 1999. e-speak Design and Architecture, Version 1.1. Cupertino: Hewlet Packard Co. http://www.commerce.net/other/research/technology-applications/1999/99_27_r.pdf
Hoque, R. 1998. CORBA 3. Foster City: IDG Books Worldwide.
Li, S. 2001. JXTA: Peer-to-Peer Computing with Java, WROX: Birmingham.
Microsoft. 2002. .NET Product Overview, http://msdn.microsoft.com/netframework/productinfo/overview/default.asp.
Mills, D.L. 1981. RFC 799: Internet name domains. IETF.
Negroponte, N. 1995. Being Digital, New York: Knopf.
Garcia, L.D. 1992. Global Standards: Building Blocks for the Future. TCT-512. Washington DC: Government Printing Office.
Ogbuji, U. 2002. The Languages of the Semantic Web. New Architect 7(6): 30-33.
Oksala, S., Rutkowski, A., Spring, M.B. & O’Donnell, J. 1996. The Structure of IT Standardization. StandardView 4(1): 9-22.
Postel, J. & Su, Z. 1982. RFC 819: Domain naming convention for Internet user applications. IETF.
Simon, H. 1981. The Sciences of the Artificial (Second Edition). Cambridge: MIT Press.
Spring, M.B. 1996. Reference Model for Data Interchange Standards. IEEE Computer 29(8): 87-88.
Spring, M.B., Jamison, W., Fithen, K.T., & Thomas, P. 1990. Preliminary Notes: Human-Computer Interaction Reference Model (HIRM). SLIS Research Report LIS032/IS90010.
Spring, M.B., Jamison, W., Fithen, K.T., Thomas, P. & Pavol, R. 1991. Rationale, Policy Issues, and Architectural Considerations for a Human-Computer Interaction Reference Model (HIRM). SLIS Research Report LIS043/IS91011 .
Spring, M.B. & Weiss, M.B. 1995. Financing the Standards Development Process. In B. Kahin and J. Abbate (Eds.), Standards Policy for Information Infrastructure. Cambridge: MIT Press.
Swartz, A. The Semantic Web In Breadth. http://logicerror.com/semanticWeb-long.
The Semantic Web: An Introduction. http://infomesh.net/2001/swintro/ .
Weiss, M. B.H. & Cargill C. 1992. A Theory of Consortia in IT Standards Setting. Journal of the American Society for Information Science 43(8): 559-565.
Weiss, M. B.H. 1993. The Standards Development Process: A View From Political Theory. ACM StandardView 1(3).