BIG DATA PROCESSING IN THE CLOUD:
In the recent years, cloud computing and its pay-as-you-go cost structure have enabled infrastructure providers, platform providers and application service providers to offer computing services on demand and pay per use just like how we use utility today. This growing trend in cloud computing, combined with the demands for Big Data and Big Data analytics, is driving the rapid evolution of datacenter technologies towards more cost-effective, more consumer-driven, more privacy conscious and technology agnostic solutions. One of the technologies that made big data analytics popular and accessible to enterprises of all sizes is MapReduce and its open-source implementation namely Hadoop. With the ability to automatically parallelize the application on a cluster of commodity hardware, MapReduce allows enterprises to analyze terabytes and petabytes of data more conveniently than ever. It is estimated that, by 2015, more than half the world's data will be processed by Hadoop. As part of our research, we have identified and tackled some of the important challenges in scaling MapReduce-based Big Data computing in Cloud datacenters.
Purlieus:
Coupled Storage Architecture for MapReduce:
The network load of MapReduce is of special concern in a datacenter as large amounts of data can be generated during the shuffle phase of the MapReduce job. As each reduce task needs to read the output of all map tasks, a sudden explosion of network traffic can significantly deteriorate cloud performance. Purlieus is a self-configurable locality-based data and virtual machine management framework that enables MapReduce jobs to access most of their data either locally or from close-by nodes including all input, output and intermediate data generated during map and reduce phases of the jobs. The first feature of Purlieus is to identify and categorize jobs using a data-size sensitive classifier to characterize jobs using four data size based footprint. Purlieus then provisions virtual MapReduce clusters in a locality-aware manner, enabling efficient pairing and allocation of MapReduce virtual machines (VMs) to reduce the network distance between storage and compute nodes for both map and reduce processing. Through this careful combination of data locality and VM placement, Purlieus achieves significant savings in network traffic and almost 50% reduction in job execution times.
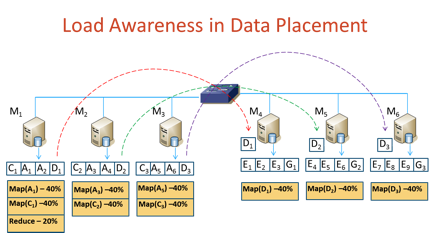
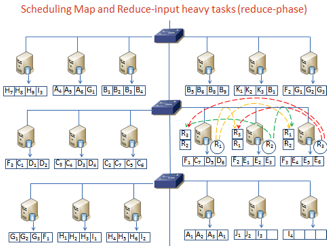
Figure 2:
Load-aware Data Placement and Reduce-locality aware Scheduling
While map locality is well understood and implemented
in MapReduce systems, reduce locality has surprisingly received little
attention in spite of its significant potential impact. As an example, Figure 3
shows the impact of improved reduce locality for a Sort workload. It shows the
Hadoop task execution timelines for a 10 GB dataset in a 2-rack 20-node
physical cluster where 20 Hadoop VMs were placed without and with reduce
locality (top and bottom figures respectively). As seen from the graph, reduce
locality resulted in a significantly shorter shuffle phase helping reduce total
job runtime by 4x. Purlieus categorizes MapReduce jobs based on how much data
they access during the map and reduce phases and analyzes the network flows
between sets of machines that store the input/intermediate data and those that
process the data. It places data on those machines that can either be used to process
the data themself or are close to the machines that can do the processing. This
is in contrast to conventional MapReduce systems which place data independent
of map and reduce computational placement -- data is placed on any node in the
cluster which has sufficient storage capacity and only map tasks are attempted
to be scheduled local to the node storing the data block. To the best of our
knowledge, Purlieus is the first effort that attempts to improve data locality
for MapReduce in a cloud.
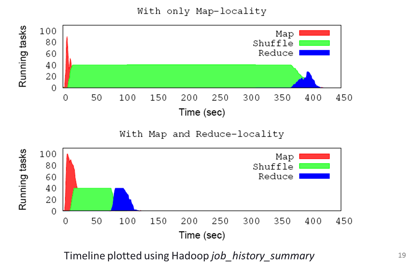
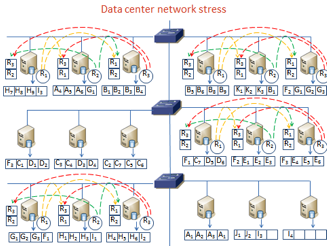
Figure 3:
Impact of Reduce Locality and Reduced Network stress
Cura: A Cost-optimized
Model for MapReduce Clouds:
One of the most challenging goals of Cloud providers is to determine how to best provision virtual MapReduce clusters for jobs submitted to the cloud by taking into consideration two sometimes conflicting requirements namely, on one hand, meeting the service quality requirements in terms of throughputs and response times and on the other hand minimizing the overall consumption cost of the MapReduce cloud data center. We propose a new Cost-optimized model for MapReduce in a Cloud called Cura. In contrast to existing MapReduce cloud services, the resource management techniques in Cura aim at minimizing the overall resource utilization in the cloud as opposed to per-job or per-customer resource optimization in the existing services. This global optimization in Cura in combination with other enhancements such as cost-aware resource provisioning, VM-aware scheduling, intelligent capacity planning and online virtual machine reconfiguration results in more than 80% reduction in the compute infrastructure cost of the cloud data center with 65% lower response time for the jobs.
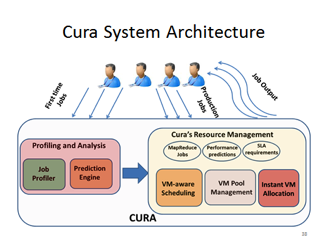
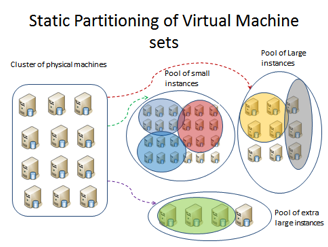
Figure 4:
Cura: System Architecture and Virtual Machine Pools
VNCache: Seamless
Caching for Bridging Compute and Storage Clouds :
Most existing services for MapReduce in the Cloud violate the fundamental design philosophy of MapReduce namely moving compute towards the data. Therefore, processing big data is inefficient with the existing Cloud storage models where data requires to be transferred from the storage cloud to the compute cloud before any jobs can be run. Further while the (often long running) job is executing, the dataset is replicated multiple times in both storage and compute clouds. We developed an efficient filesystem layer VNcache that integrates a virtual namespace of data stored in the storage cloud into the compute cluster. Through a seamless data streaming model, VNcache optimizes Hadoop jobs as they can start executing as soon as the compute cluster is launched without requiring apriori data transfer. With VNcache's accurate pre-fetching and caching, jobs often run on a local cached copy of the data block significantly improving performance. Further data can be safely evicted from the compute cluster as soon as it is processed reducing the total storage footprint. Uniquely, VNcache is implemented with no changes to the Hadoop application stack and provides a flexible control point for cloud providers to seamlessly introduce storage hierarchies including SSD based storage into the solution.
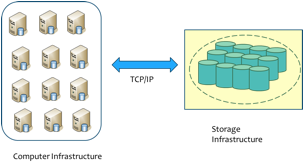
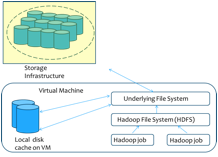
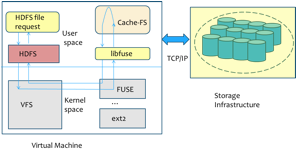
Figure 5:
VNCache: Data Flow
Reliable State Monitoring in Cloud Datacenters:
Continuously delivering accurate state monitoring results in the Cloud is difficult with transient node failures or network issues that are common in large-scale datacenters. As the scale of such systems grows and the degree of workload consolidation increases in Cloud datacenters, node failures and performance interferences, especially transient ones, become the norm rather than the exception. Hence, distributed state monitoring tasks are often exposed to impaired communication caused by such dynamics on different nodes. Unfortunately, existing distributed state monitoring approaches are often designed under the assumption of always online distributed monitoring nodes and reliable inter-node communication. As a result, these approaches often produce misleading results which in turn introduce various problems to Cloud users who rely on state monitoring results to perform automatic management tasks such as auto-scaling. This work introduces a new state monitoring approach that tackles this challenge by exposing and handling communication dynamics such as message delay and loss in Cloud monitoring environments. Our approach delivers two distinct features. First, it quantitatively estimates the accuracy of monitoring results to capture uncertainties introduced by messaging dynamics. This feature helps users to distinguish trustworthy monitoring results from ones heavily deviated from the truth, yet significantly improves monitoring utility compared with simple techniques that invalidate all monitoring results generated with the presence of messaging dynamics. Second, our approach also adapts to non-transient messaging issues by reconfiguring distributed monitoring algorithms to minimize monitoring errors. Our experimental results show that, even under severe message loss and delay, our approach consistently improves monitoring accuracy, and when applied to Cloud application auto-scaling, outperforms existing state monitoring techniques in terms of the ability to correctly trigger dynamic provisioning.
Related Publications:
· Balaji Palanisamy, Aameek Singh and Ling Liu, "Cost-effective
Resource Provisioning for MapReduce in a
Cloud", to appear in IEEE
Transactions on Parallel and Distributed Systems (IEEE TPDS 2014). (Pdf)
· Balaji Palanisamy, Aameek Singh, Ling Liu and Bhushan Jain, "Purlieus: Locality-aware Resource Allocation for MapReduce in a Cloud", Proc. of IEEE/ACM Supercomputing (SC' 11). (Pdf)
· Balaji Palanisamy, Aameek Singh, Ling Liu and Bryan Langston, "Cura: A Cost-Optimized Model for MapReduce in a Cloud", Proc. of 27th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2013). (Pdf)
· Balaji Palanisamy, Aameek Singh, Nagapramod
Mandagere, Gabriel Alatore
and Ling Liu, "VNCache: Map Reduce Analysis for Cloud-archived Data", Proc. of
14th IEEE/ACM International Symposium on
Cluster, Cloud and Grid Computing (IEEE/ACM CCGrid
’14) (Pdf)
· Shicong Meng, Arun Iyengar, Isabelle Rouvellou, Ling Liu, Kisung Lee,
Balaji Palanisamy and Yuzhe Tang, "Reliable State Monitoring
with Messaging Quality Awareness", Proc. of IEEE International Conference on Cloud Computing (IEEE Cloud' 12).
(Pdf)
(Received Best Paper Award)
Patents:
· Balaji Palanisamy and Aameek Singh, "Locality-aware Resource Allocation for Cloud Computing", United States Patent Application No. 13/481,614